
Слайд 17Недостаток микропроцессоров для ЦОС состоит в их структурной ограниченности направленной на
получение предельной производительности при выполнении строго определённых вычислений, что приводит к ограничению числа одновременно задействованных операционных устройств и поэтому не позволяющего эффективно использовать естественный параллелизм алгоритмов ЦОС
Поэтому важное значение имеет второе направление предполагает максимальное распараллеливание процесса обработки информации с целью получения наибольшего выигрыша в производительности при решении конкретной задачи.Такой подход реализован на основе универсальных вычислительных ячеек (УВЯ) на базе программируемых логических матриц (ПЛМ или ПЛИС).В случае использования УВЯ для каждой вычислительной процедуры используется своя группа таких вычислительных ячеек (так называемый настраиваемый процессор). Программа загружается один раз перед началом решения задачи, а обработка потоков информации производится без промежуточного запоминания результатов, т.е
работает по принципу конвейера, который на одном конце с каждым тактом загружается информацией, а на другом конце конвейера производится выгрузка результата обработки информации.Общая структура вычислительной системы обеспечивает параллельную организацию множества конвейеров, в том числе охваченных обратными связями.Особенностью такой вычислительной системы является отсутствие устройств управления, ОЗУ, магистрали данных, а также наличие большого количества информационных входов и выходов.Подобные структуры вычислительных систем ЦОС на однородных средах называются систолическими структурами.
Использование ПЛИС для ЦОС

1.1. Основные понятия и определения в области организации вычислительных систем
Рассмотрим базовые концепции, которые лежат в основе любой вычислительной системы, от простейшего микроконтроллера до сложного компьютера – базовая терминология вычислительной техники, принципы организации микропроцессорных систем, структура связей, режимы работы и основные типы вычислительной систем.
Введем несколько основных определений.
Электронная система – в данном случае это любой электронный узел, блок, прибор или комплекс, производящий обработку информации.
Задача – это набор функций, выполнение которых требуется от электронной системы.
Быстродействие – это показатель скорости выполнения электронной системой ее функций.
Гибкость – это способность системы подстраиваться под различные задачи.
Избыточность – это показатель степени соответствия возможностей системы решаемой данной системой задаче.
Интерфейс – соглашение об обмене информацией, правила обмена информацией, подразумевающие электрическую, логическую и конструктивную совместимость устройств, участвующих в обмене. Другое название – сопряжение.
Вычислительная система (микропроцессорная система (МПС)) может рассматриваться как частный случай электронной системы, предназначенной для обработки входных сигналов и выдачи выходных сигналов (рис. 1.1).
В качестве входных и выходных сигналов использоваться аналоговые сигналы, одиночные цифровые сигналы, цифровые коды, последовательности цифровых кодов. Внутри системы производиться хранение, накопление сигналов (или информации).
 Рисунок 1.1 – Электронная система
Рисунок 1.1 – Электронная система
1.6. Режимы работы вычислительной системы
Как уже отмечалось, вычислительная система обеспечивает большую гибкость работы, она способна настраиваться на любую задачу. Гибкость эта обусловлена прежде всего тем, что функции, выполняемые системой, определяются программой (программным обеспечением, software), которую выполняет процессор. Но гибкость микропроцессорной системы определяется не только этим. Настраиваться на задачу помогает еще и выбор режима работы системы, то есть режима обмена информацией по системной магистрали (шине).
Практически любая развитая вычислительная (микропроцессорная) система поддерживает три основных режима обмена по системной магистрали:
— программный обмен информацией;
— обмен с использованием прерываний (Interrupts);
— обмен с использованием прямого доступа к памяти(ПДП, DMA – Direct Memory Access).
Программный обмен информацией является основным в любой микропроцессорной системе. Он предусмотрен всегда, без него невозможны другие режимы обмена. Все операции (циклы) обмена информацией в данном случае инициируются только процессором, все они выполняются строго в порядке, предписанном исполняемой программой. Процессор читает (выбирает) из памяти коды команд и исполняет их, читая данные из памяти или из устройства ввода/вывода, обрабатывая их, записывая данные в память или передавая их в устройство ввода/вывода.
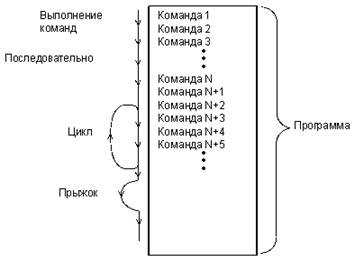
Путь процессора по программе может быть линейным, циклическим, может содержать переходы (прыжки), но он всегда непрерывен и полностью находится под контролем процессора. Ни на какие внешние события, не связанные с программой, процессор не реагирует (рис. 1.8).
|
|
|
Рисунок 1.8 – Программный обмен информацией |
Обмен по прерываниям используется тогда, когда необходима реакция микропроцессорной системы на какое-то внешнее событие, на приход внешнего сигнала. В случае компьютера внешним событием может быть, например, нажатие на клавишу клавиатуры или приход по локальной сети пакета данных. Компьютер должен реагировать на это, соответственно, выводом символа на экран или же чтением и обработкой принятого по сети пакета.
В общем случае организовать реакцию на внешнее событие можно тремя различными путями:
— с помощью постоянного программного контроля факта наступления события (так называемый метод опроса флага или polling);
— с помощью прерывания, то есть насильственного перевода процессора с выполнения текущей программы на выполнение экстренно необходимой программы;
— с помощью прямого доступа к памяти, то есть без участия процессора при его отключении от системной магистрали.
Первый случай с опросом флага реализуется в микропроцессорной системе постоянным чтением информации процессором из устройства ввода/вывода, связанного с тем внешним устройством, на поведение которого необходимо срочно реагировать.
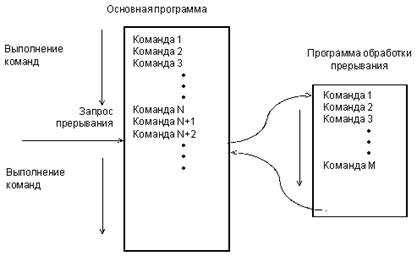
Во втором случае в режиме прерывания процессор, получив запрос прерывания от внешнего устройства (часто называемый IRQ – Interrupt ReQuest), заканчивает выполнение текущей команды и переходит к программе обработки прерывания. Закончив выполнение программы обработки прерывания, он возвращается к прерванной программе с той точки, где его прервали (рис. 1.9).
|
|
|
Рисунок 1.9 – Обслуживание прерывания |

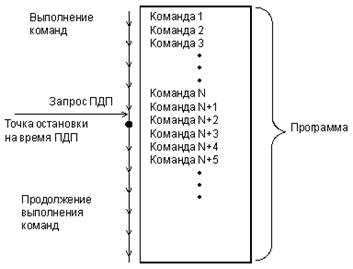
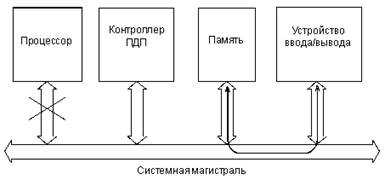
Прямой доступ к памяти (ПДП, DMA) – это режим, принципиально отличающийся от двух ранее рассмотренных режимов тем, что обмен по системной шине идет без участия процессора. Внешнее устройство, требующее обслуживания, сигнализирует процессору, что режим ПДП необходим, в ответ на это процессор заканчивает выполнение текущей команды и отключается от всех шин, сигнализируя запросившему устройству, что обмен в режиме ПДП можно начинать. Операция ПДП сводится к пересылке информации из устройства ввода/вывода в память или же из памяти в устройство ввода/вывода. Когда пересылка информации будет закончена, процессор вновь возвращается к прерванной программе, продолжая ее с той точки, где его прервали (рис. 1.10). Это похоже на режим обслуживания прерываний, но в данном случае процессор не участвует в обмене. Контроллер ПДП может считаться специализированным процессором, который отличается тем, что сам не участвует в обмене, не принимает в себя информацию и не выдает ее (рис. 1.11).
|
|
|
Рисунок 1.10 – Обслуживание ПДП |
|
|
|
Рисунок 1.11 – Информационные потоки в режиме ПДП |
Слайд 15Особенности архитектуры ЦПОСпрограммы выполняются, как правило, в реальном масштабе времени —
по мере поступления входного сигнала, что придает критическую важность вопросам повышения быстродействия;программы содержат много логических и особенно арифметических операций и практически не содержат программ перехода;происходит постоянный и быстрый ввод вывод данных, зачастую в аналоговой формепрограммы относительно короткие и достаточно редко изменяются, зачастую остаются неизменными на протяжении всего срока эксплуатации процессора. Особенностью программ цифровой обработки сигналов
Особенностью программ цифровой обработки сигналов
Особенности архитектуры
часто используется Гарвардская архитектура;большая (иногда нестандартная) разрядность обрабатываемых данных – 24, 32, 48, 64, 128, что позволяет увеличить диапазон обрабатываемых чисел без применения формата с плавающей запятой или обрабатывать по несколько чисел одновременно;аппаратные блоки, предназначенные для ускорения выполнения команды умножения – сдвиговые регистры, матричные умножители;память команд и данных расположены на самом кристалле процессора;возможность параллельного выполнения нескольких операций одновременно, например, ввода вывода и арифметических команд;все команды имеют одинаковую длину и выполняются за одинаковое время, что позволяет использовать счетчик команд для отсчета временных интервалов.ортогональная система команд.







Слайд 10Рис. 3. Архитектура с общей шиной команд и данныхФон-Неймановская (Принстонская) архитектура
организации процессора
Единая шина для данных и команд. В составе системы присутствует одна общая память, как для данных, так и для команд
Принципы фон Неймана (1946 г.)
1. Принцип программного управления.Программа состоит из набора команд, которые выполняются процессором друг за другом в определенной последовательности.2. Принцип однородности памяти.Как программы (команды), так и данные хранятся в одной и той же памяти (и кодируются в одной и той же системе счисления – чаще всего двоичной). Над командами можно выполнять такие же действия, как и над данными.3. Принцип адресуемости памяти.Структурно основная память состоит из пронумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка.

Как на практике работает сетевая модель OSI
В начале статьи мы задались вопросом: а как передаются сообщения в Telegram? Настало время на него ответить — и показать весь процесс передачи данных по модели OSI.
Мы хотим отправить сообщение нашему другу. Печатаем текст и нажимает кнопку «Отправить», а дальше перемещаемся внутрь компьютера.
Прикладной уровень. Приложение Telegram работает на прикладном уровне модели OSI. Когда мы печатаем текст сообщения и нажимаем кнопку «Отправить», эти данные передаются на сервер мессенджера, а оттуда — нашему другу.
Весь процесс проходит через API разных библиотек — например, для HTTP-запросов. Интерфейсы позволяют без лишних проблем обмениваться данными и не погружаться в то, как они представлены на низком уровне. Всё, что нужно знать, — это какую функцию вызвать и какие переменные туда передать.
Уровень представления. Здесь данные должны преобразоваться в унифицированный формат, чтобы их можно было передавать на разные устройства и операционные системы. Например, если мы отправляем сообщение c Windows на macOS, данные должны быть в читаемом для компьютеров Apple виде. Такая же ситуация и с другими устройствами.
Раз мы собираемся передать данные на другой компьютер, их нужно перевести в бинарный формат. После этого начнётся сам процесс передачи по сети.
Сеансовый уровень. Чтобы данные успешно передались сначала на сервер Telegram, а затем к нашему другу, приложению нужно установить соединение, или сеанс. Он обеспечивает синхронизацию между устройствами и восстанавливает связь, если она прервалась.
Благодаря сеансам вы можете видеть, что собеседник что-то печатает или отправляет вам картинки или видео. Но главная задача этого соединения — обеспечить стабильное соединение для передачи данных.
Транспортный уровень. Когда соединение установлено и данные унифицированы, пора передавать их. Этим занимается транспортный уровень.
Здесь данные разбиваются на сегменты и к ним добавляется дополнительная информация — например, номер порта и контрольные суммы. Всё это нужно, чтобы данные дошли до пользователя в целостности.
Сетевой уровень. Теперь данным нужно найти маршрут к устройству нашего друга, а затем отправить их по нему. Поэтому данные упаковываются в пакеты и к ним добавляются IP-адреса.
Чтобы получить IP-адрес устройств, которым нужно отправить пакеты, маршрутизаторы (устройства сетевого уровня) обращаются к ARP. Этот протокол быстро найдёт адрес получателя и отдаст его нам.
Канальный уровень. Здесь данные передаются от одного MAC-адреса к другому. Изначальный текст делится на фреймы — с заголовками и контрольными суммами для проверки целостности данных.
Физический уровень. И на самом нижнем уровне данные в виде электрических сигналов передаются по проводам, кабелям или по радиоволнам. Тут только одна задача — как можно быстрее откликаться на сигналы свыше.
Слайд 5Разрядность шины данных определяет скорость работы системы.Разрядность шины адреса определяет допустимую
сложность системы.Количество линий управления определяет разнообразие режимов обмена и эффективность обмена процессора с другими устройствами системы.Чем больше тактовая частота процессора, тем он быстрее выполняет команды. Быстродействие процессора определяется не только тактовой частотой, но и особенностями его структуры (архитектуры) Основные характеристики определяющие производительность микропроцессора:
Набор регистров для хранения промежуточных данныхСистема команд процессораСпособы адресации операндов в пространстве памятиОрганизация процессов выборки и использования команд
Важнейшие характеристики процессора — это количество разрядов его шины данных, количество разрядов его шины адреса и количество управляющих сигналов в шине управления.

Слайд 14Особенности структуры микропроцессора для цифровой обработки сигналовВ отличии от микропроцессоров с
универсальной структурой микропроцессоры предназначенные для цифровой обработки сигналов (ЦОС, DSP – Digital Signal Processing) обладают определённой структурной специализацией, обусловленной характером решаемых ими задач в составе вычислительных средств первичной обработки информации.В настоящий момент имеются два основных структурных направления развития быстродействующих микропроцессоров этой группы:
Специализированные микропроцессоры для ЦОС, структура которых ориентирована на решение относительно широкого класса задач ЦОС, множество которых ограничено только допустимым частотным диапазоном обработки сигналов в реальном времениМикросхемы с узкоспециализированной структурой, обеспечивающей достижение наибольшей производительности при решении конкретной задачи.

2-й уровень OSI — канальный (L2, data link layer)
Над физическим уровнем располагается канальный. Его задача — проверить целостность полученных данных и исправить ошибки. Этот уровень «поумнее» предыдущего: он уже понимает, что разные амплитуды напряжений отвечают разным битам — нулям и единицам. А ещё канальный уровень умеет кодировать сигналы в биты и передавать их дальше.
Полученные с нижнего уровня данные делятся на фреймы, или кадры. Каждый фрейм состоит из служебной информации — например, адреса отправителя и адреса получателя, — а также самих данных.

Структура фреймаИзображение: Skillbox Media
Получается что-то вроде почтового конверта. На лицевой стороне у него написано, от кого пришло письмо, а внутри находится само письмо (в нашем случае данные).
Лицевая сторона конверта — это MAC-адрес устройства, которое отправило нам информацию. Он нужен, чтобы идентифицировать устройства в локальной сети, состоит из 48 или 64 бит и выглядит примерно так:

Запись MAC-адреса в шестнадцатеричной системе счисленияИзображение: Skillbox Media
Ещё один важный факт о MAC-адресах: когда на заводе собирают ноутбук или смартфон, ему сразу же присваивают определённый MAC-адрес, который потом уже никак нельзя поменять. MAC-адрес настольных ПК зашит в сетевую карту, поэтому его можно изменить, только заменив эту самую карту.

Изображение: Skillbox Media
С помощью команды ifconfig можно узнать MAC-адрес вашего Macbook или компьютера на Linux. В Windows нужно ввести команду ipconfig.





Канальный уровень не так прост — он делится ещё на два подуровня:
- уровень управления логическим каналом — LLC (logical link control);
- уровень управления доступом к среде — тот самый MAC (media access control).
Первый подуровень нужен для взаимодействия с верхним уровнем, сетевым, а второй — для взаимодействия с нижним, физическим.
3-й уровень OSI — сетевой (L3, network layer)
Этот уровень отвечает за маршрутизацию данных внутри сети между компьютерами. Здесь уже появляются такие термины, как «маршрутизаторы» и «IP-адреса».

Маршрутизатор, который используют интернет-провайдеры. Обычно маршрутизатор — это Wi-Fi-роутерФото: Wikimedia Commons
Маршрутизаторы позволяют разным сетям общаться друг с другом: они используют MAC-адреса, чтобы построить путь от одного устройства к другому.
Данные на сетевом уровне представляются в виде пакетов. Такие пакеты похожи на фреймы из канального уровня, но используют другие адреса получателя и отправителя — IP-адреса.
Чтобы получить IP-адрес обоих устройств (отправителя и получателя), существует протокол ARP (address resolution protocol). Он умеет конвертировать MAC- в IP-адрес и наоборот.
Слайд 27В составе микропроцессорных систем, как правило, выделяются четыре специальные группы устройств
ввода/вывода:
устройства интерфейса пользователяввода информации пользователем контроллеры клавиатуры, тумблеры, отдельные кнопки, мыши, трекбол, джойстика и т.д. вывода информации для пользователя; контроллеры светодиодных индикаторов, табло жидкокристаллических, плазменных и электронно-лучевых экранов устройства ввода/вывода для длительного хранения информации; дисководами (компакт-дисков или магнитных дисков), а также с накопителями на магнитной ленте. таймерные устройства. Эти устройства предназначены для того, чтобы микропроцессорная система могла выдерживать заданные временные интервалы, следить за реальным временем, считать импульсы и т.д. устройства для подключения к информационным сетям (локальным и глобальным).

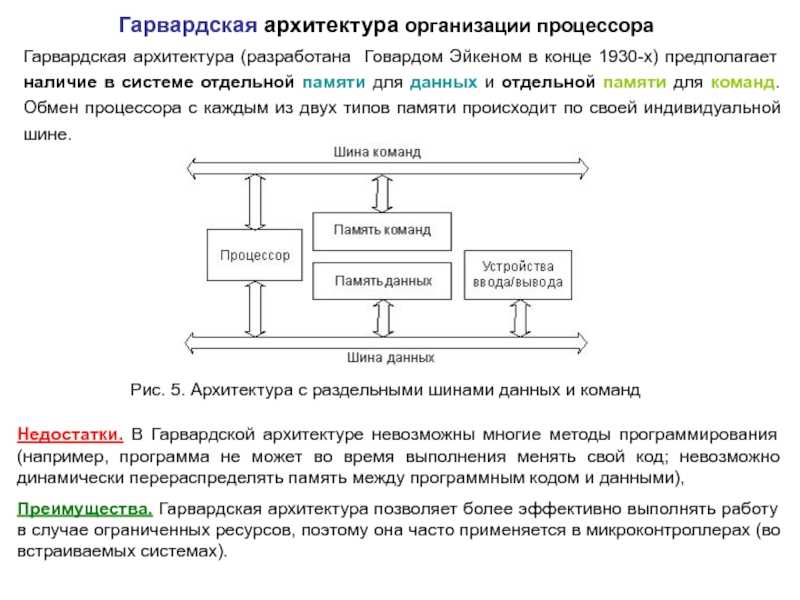
Слайд 12Гарвардская архитектура организации процессора Рис. 5. Архитектура с раздельными шинами данных
и команд
Гарвардская архитектура (разработана Говардом Эйкеном в конце 1930-х) предполагает наличие в системе отдельной памяти для данных и отдельной памяти для команд. Обмен процессора с каждым из двух типов памяти происходит по своей индивидуальной шине.
Недостатки. В Гарвардской архитектуре невозможны многие методы программирования (например, программа не может во время выполнения менять свой код; невозможно динамически перераспределять память между программным кодом и данными), Преимущества. Гарвардская архитектура позволяет более эффективно выполнять работу в случае ограниченных ресурсов, поэтому она часто применяется в микроконтроллерах (во встраиваемых системах).
4-й уровень OSI — транспортный (L4, transport layer)
Из названия понятно, что на этом уровне происходит передача данных по сети. Так и есть. Два главных протокола здесь — TCP и UDP. Они как раз и отвечают за то, как именно будут передаваться данные.
TCP (Transmission Control Protocol) — это протокол, который гарантирует доставку данных в корректном виде. Он жёстко следит за каждым битом информации, но работает гораздо медленнее UDP.
Например, когда вы вводите логин и пароль при входе в социальную сеть, очень важно, чтобы все символы отправились в определённой последовательности. Если какие-то потеряются или изменятся, вы просто не сможете авторизоваться
Поэтому протокол TCP использует разные методы проверок — например, контрольные суммы.

Для этого и нужен TCP — чтобы данные доходили в правильном видеИзображение: Skillbox Media
А вот в видео или аудио небольшие потери некритичны, зато важна скорость передачи данных. Для таких задач как раз и придумали протокол UDP (user datagram protocol). Он уже не проверяет цельность битов, его задача — как можно быстрее передать данные с одного устройства на другое.
В протоколе TCP данные делятся на сегменты. Каждый сегмент — часть пакета. Сегменты нужны, чтобы передавать информацию по сети, учитывая её пропускную способность.
Например, если вы передаёте данные с компьютера, у которого пропускная способность 100 Мб/c, на смартфон с пропускной способность 10 Мб/c, то данные разделятся так, чтобы не застревать в самом медленном устройстве.

Вот так данные разделяются на несколько сегментов, чтобы протиснуться в сеть с пропускной способностью 10 Мб/сИзображение: Skillbox Media
Ещё сегментация важна для надёжности. Один большой пакет может потеряться или направиться не тому адресату. А маленькие пакеты снижают риск подобных ошибок и даже позволяют проверять их количество. Если какой-то сегмент не получилось доставить, протокол TCP может запросить его у отправителя снова. Так обеспечивается надёжность.
Слайд 8В микропроцессорах с полным набором команд (CISC микропроцессоры) используется уровень микропрограммирования
для того, чтобы декодировать и выполнить команду микропроцессора (т.е. используются БМУ – Блок Микропрограммного Управления и УП — Управляющая Память). Достоинства− Формат команды не зависит от конструкции (аппаратуры) процессора. − На одной и той же аппаратуре при смене микропрограммы могут быть реализованы различные микропроцессоры. С точки зрения пользователя у микропроцессора только увеличивается производительность, снижается потребление энергии, уменьшаются габариты устройств.− Изменение конструкции (аппаратуры) никак не влияет на программное обеспечение микропроцессора.Недостаток− Производители микросхем стараются увеличить количество команд, которые может выполнять микропроцессор, тем самым увеличивая сложность микропрограммы и замедляя выполнение каждой команды в целом.

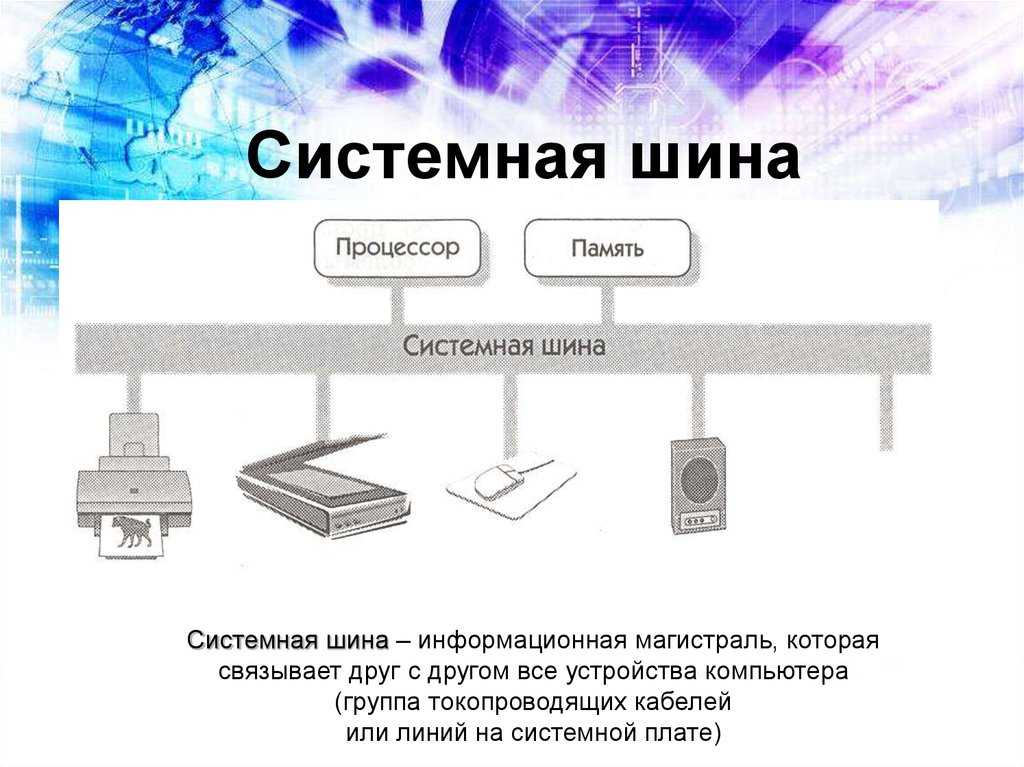
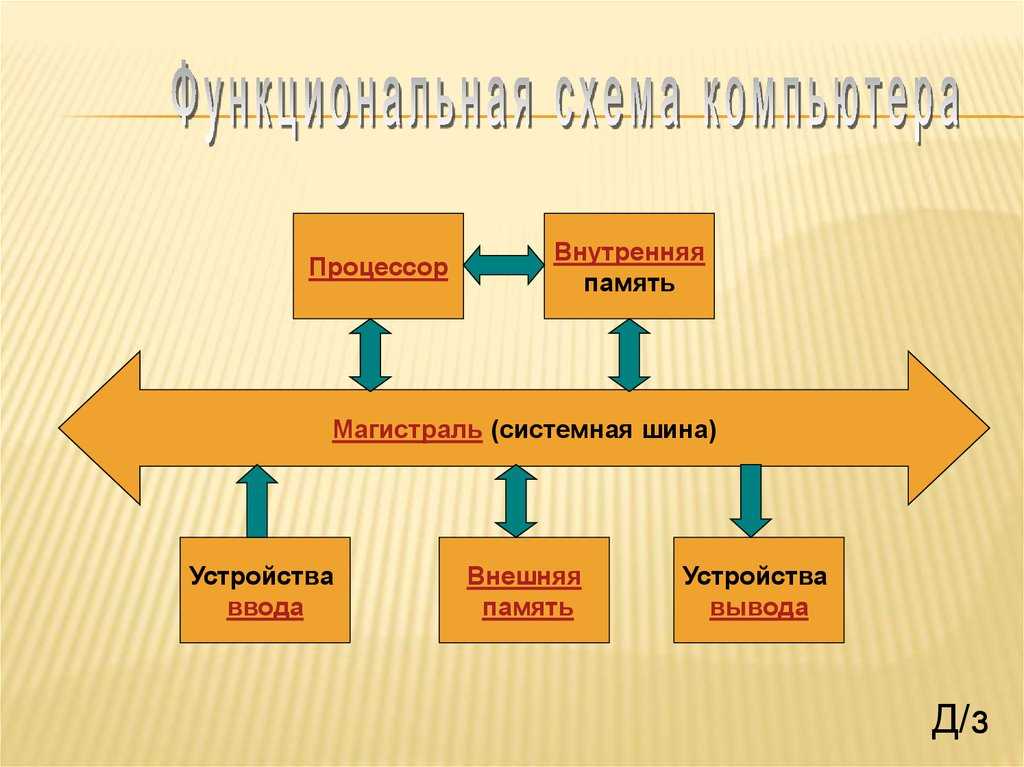
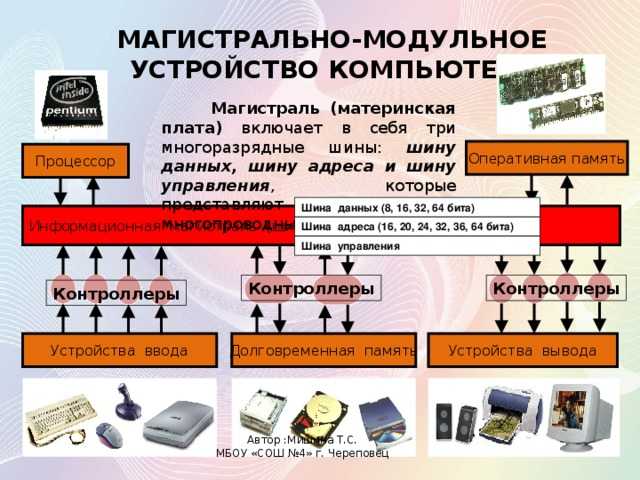
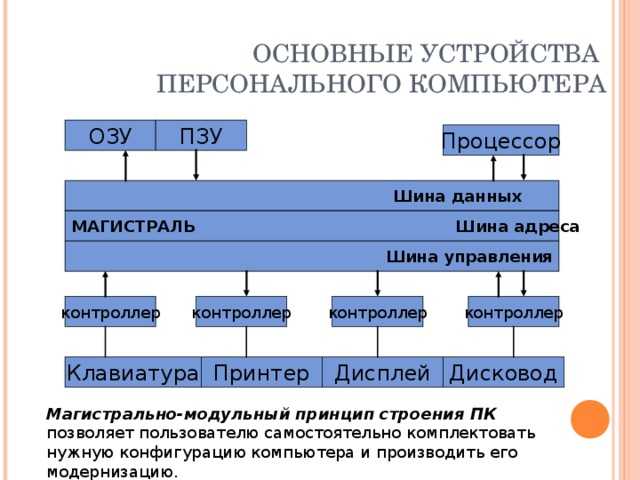
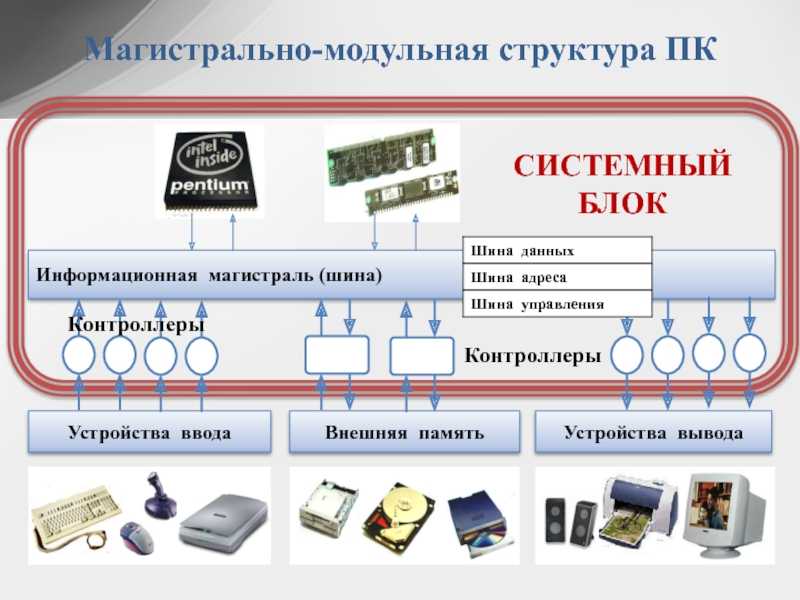
Магистрально-модульный принцип
В основе архитектурного построения сегодняшних электронных вычислительных машин положены магистрально-модульные принципы. Модульность конструкции даёт возможность пользователям самим определять комплектацию и, как следствие, конфигурацию своих компьютеров, а в дальнейшем и модернизировать их, по мере необходимости.
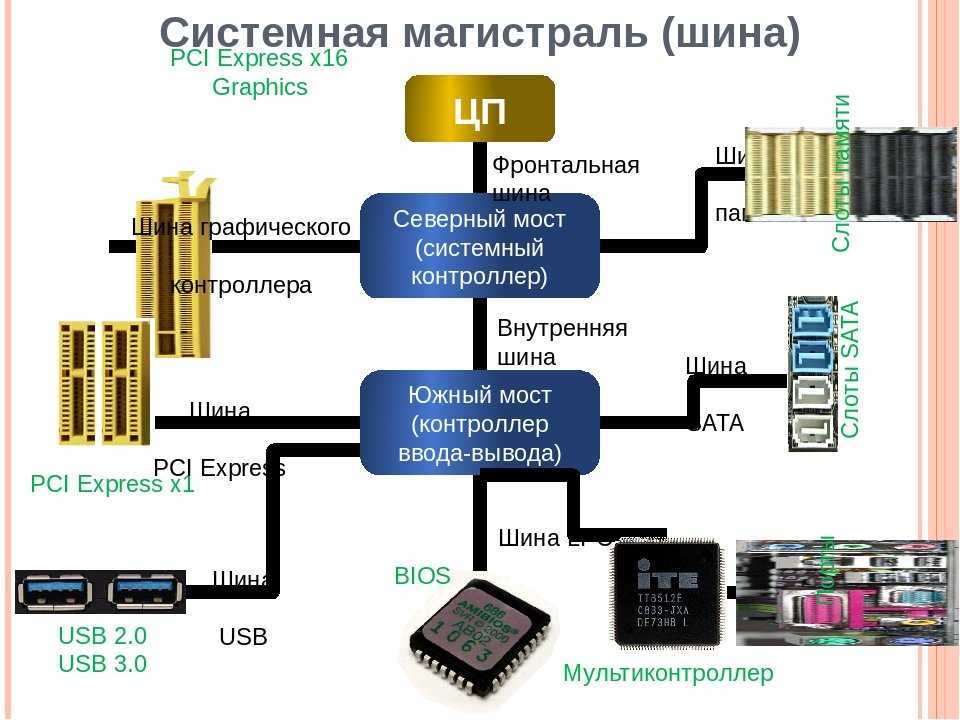
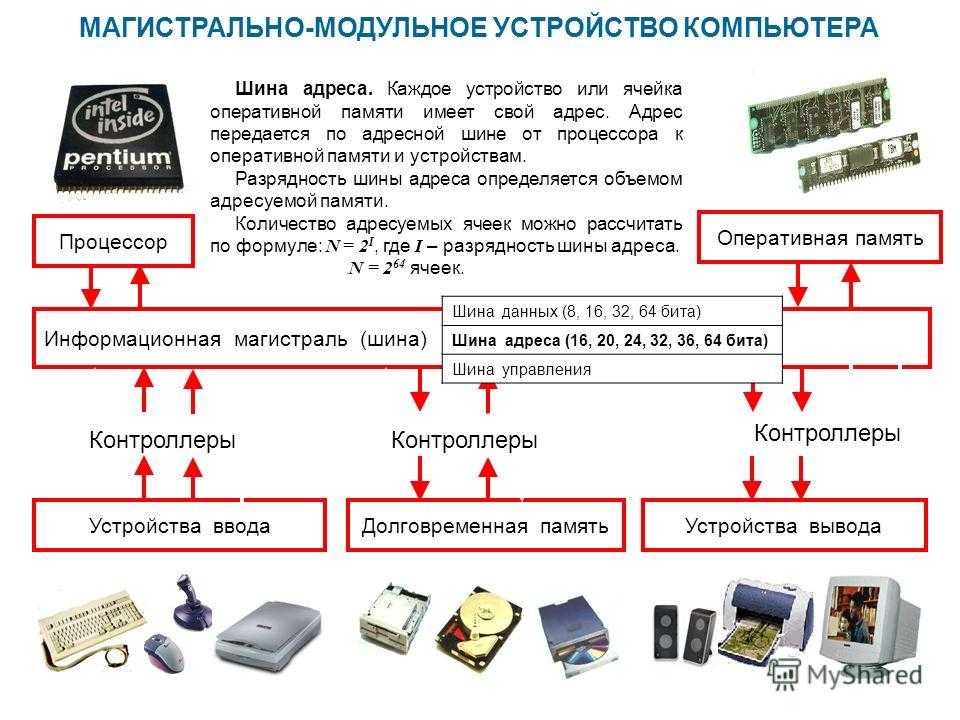
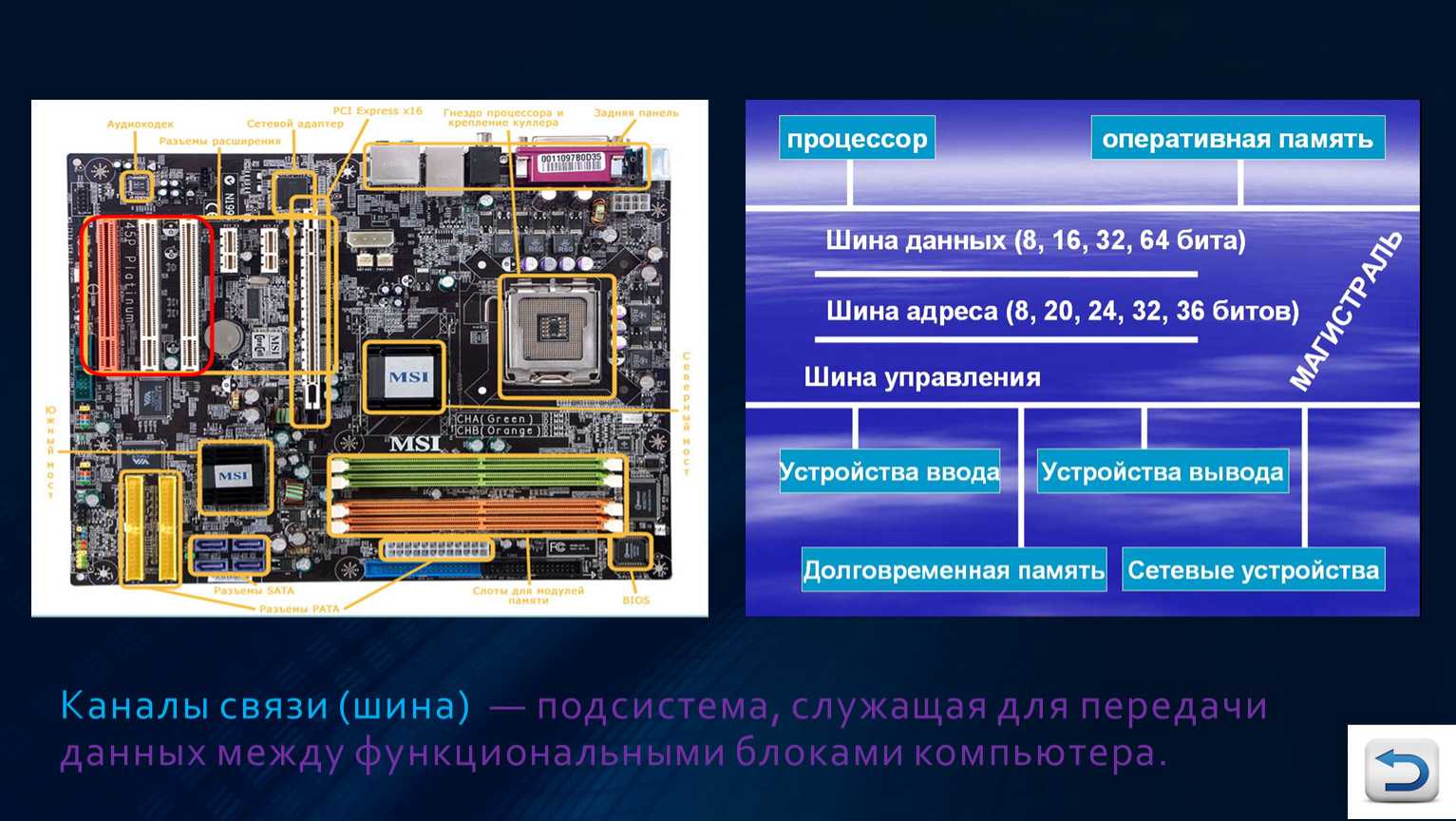
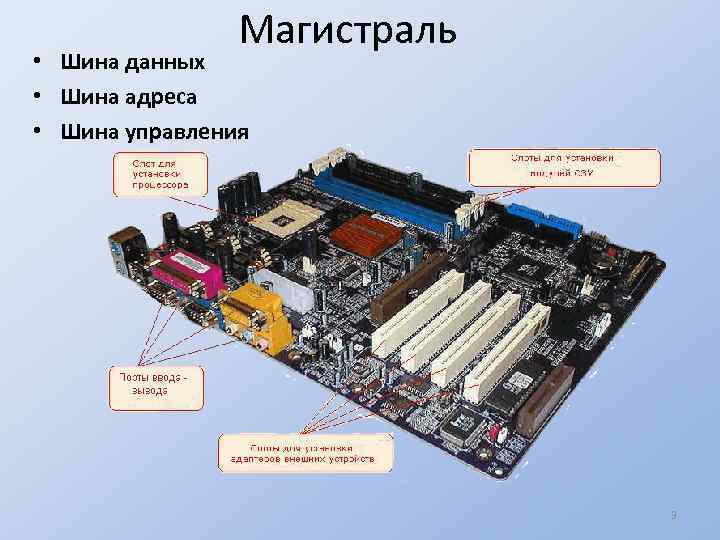
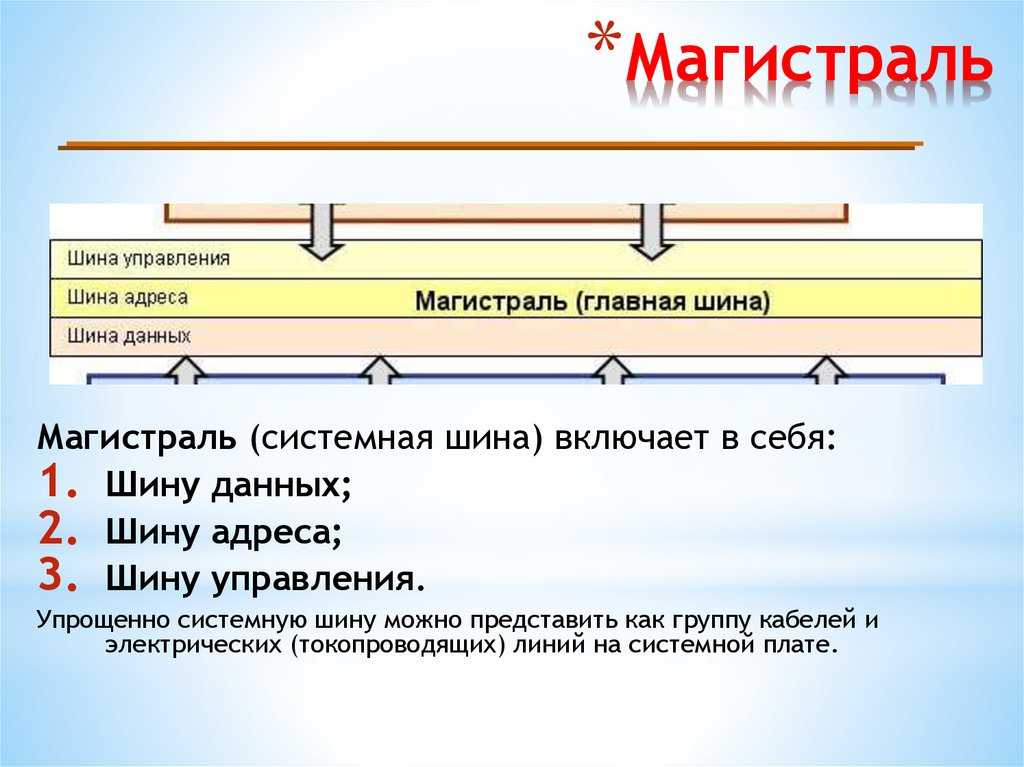
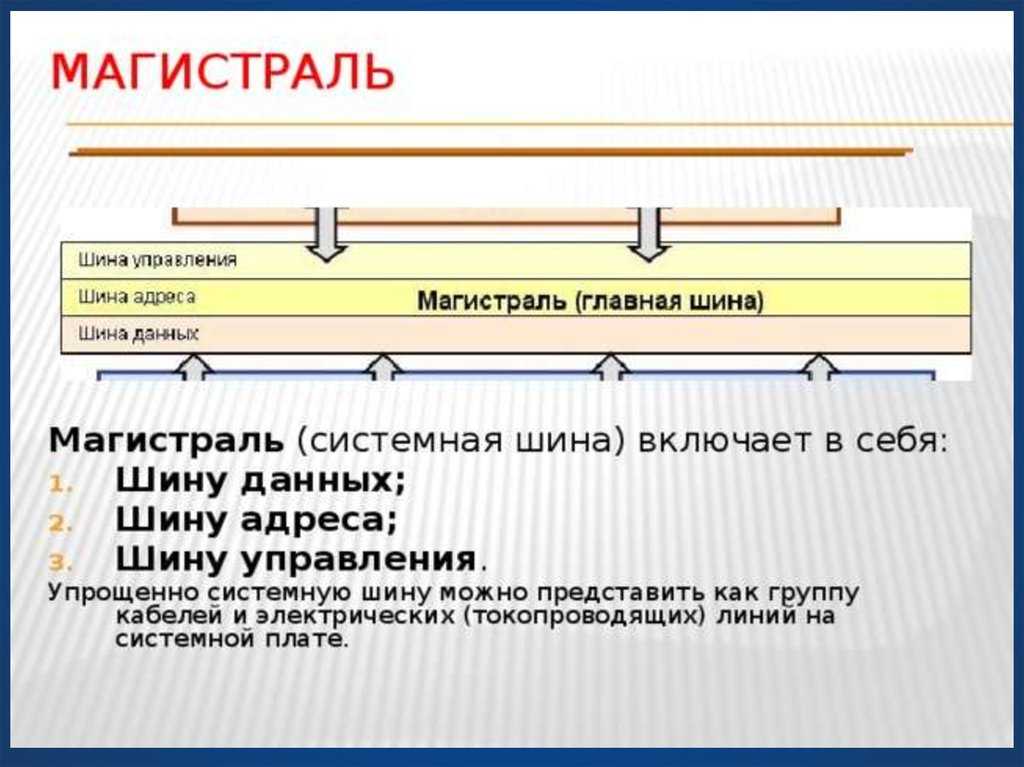
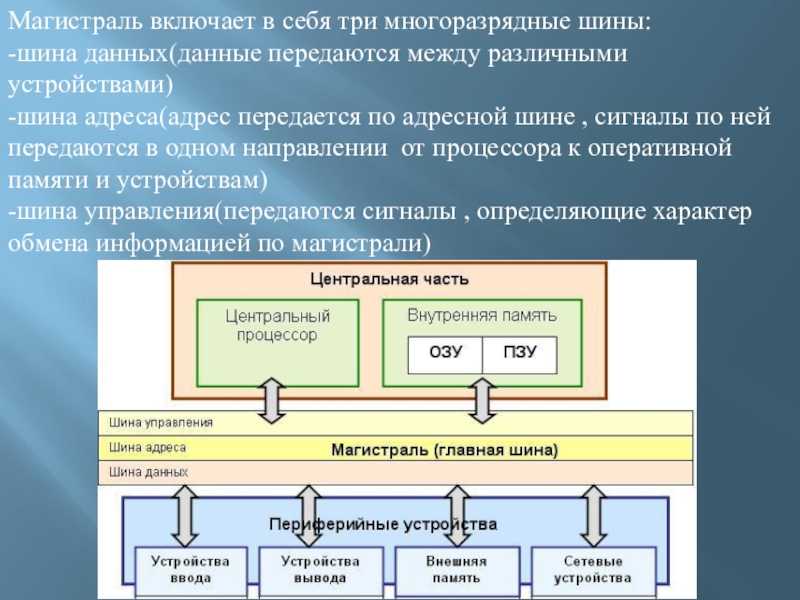
Главной опорой модульности можно считать магистральную методику передачи информационных данных между модулями и устройствами. Магистраль, она же системная шина, состоит из трёх многоразрядных шин:
Получи помощь с рефератом от ИИ-шки
ИИ ответит за 2 минуты
- Шина данных.
- Шина адреса.
- Шина управления.
По шине данных выполняется обмен данным между модулями. К примеру, осуществляется выборка данных из оперативной памяти и передача их процессору, который их обрабатывает и направляет обратно в оперативную память или на модули вывода. Возможна передача данных между модулями в разных направлениях. Число разрядов шины данных равно разрядности процессора, то есть числу двоичных разрядов, обрабатываемых процессором за один тактовый период.
Шина адреса служит для определения процессором модуля или ячейки памяти, с которой будет выполняться обмен информационными данным. Всем модулям и ячейкам памяти присвоены свои оригинальные адреса. Код адреса пересылается по шине адреса, при этом посылаются эти коды только в направлении от процессора к другим устройствам. Число разрядов адресной шины определяет формат адресного пространства процессора. При 32-х разрядном процессоре его адресное пространство составит четыре Гбайта.
Шина управления служит для передачи управляющих сигналов, определяющих какой тип операции следует исполнить (запись или считывание данных, синхронизацию обмена и так далее).
Слайд 7Система команд может быть:Ортогональная – все команды фиксированной длины, имеют одинаковое
время исполнения (преимущественно за один цикл (такт) синхронизации, равноправное использование всех регистров процессораНеортогональная – не все команды могут использовать весь набор возможных способов адресации применительно к любому из регистров процессора
С точки зрения системы команд и способов адресации операндов в основном различают две архитектуры процессоров
RISC (Reduced Instruction Set Computer) процессоры (процессоры с сокращённым набором команд) CISC (Complicated Instruction Set Computer) процессоры (процессоры с полным набором команд)
Архитектурой микропроцессора называется комплекс его аппаратных и программных средств, предоставляемых пользователю. В это общее понятие входит набор программно-доступных регистров и исполнительных (операционных) устройств, система основных команд и способов адресации, объем и структура адресуемой памяти, виды и способы обработки прерываний. При описании архитектуры и функционирования процессора обычно используется его представление в виде совокупности программно-доступных регистров, образующих регистровую или программную модель. В регистровую модель входит группа регистров общего назначения, служащих для хранения операндов, и группа служебных регистров, обеспечивающих управление выполнением программы и режимом работы процессора, организацию обращения к памяти (защита памяти, сегментная и страничная организация и др.).



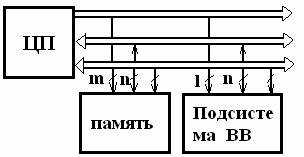



1.7. Архитектура микропроцессорных систем
До сих пор мы рассматривали только один тип архитектуры микропроцессорных систем – архитектуру с общей, единой шиной для данных и команд (одношинную, или принстонскую, фон-неймановскую архитектуру). Соответственно, в составе системы в этом случае присутствует одна общая память, как для данных, так и для команд (рис. 1.12).
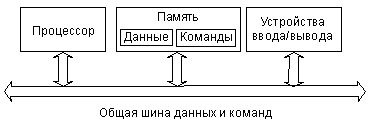 Рисунок 1.12 – Архитектура с общей шиной данных и команд
Рисунок 1.12 – Архитектура с общей шиной данных и команд
Но существует также и альтернативный тип архитектуры микропроцессорной системы – это архитектура с раздельными шинами данных и команд (двухшинная, или гарвардская, архитектура). Эта архитектура предполагает наличие в системе отдельной памяти для данных и отдельной памяти для команд (рис. 1.13). Обмен процессора с каждым из двух типов памяти происходит по своей шине.
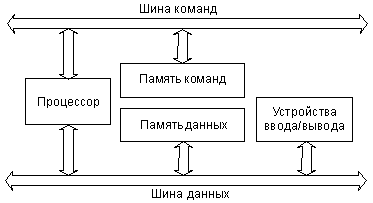 Рисунок1.13 – Архитектура с раздельными шинами данных и команд
Рисунок1.13 – Архитектура с раздельными шинами данных и команд
Архитектура с общей шиной распространена гораздо больше, она применяется, например, в персональных компьютерах и в сложных микрокомпьютерах. Архитектура с раздельными шинами применяется в основном в однокристальных микроконтроллерах.
Рассмотрим некоторые достоинства и недостатки обоих архитектурных решений.
Архитектура с общей шиной (принстонская, фон-неймановская) проще, она не требует от процессора одновременного обслуживания двух шин, контроля обмена по двум шинам сразу. Наличие единой памяти данных и команд позволяет гибко распределять ее объем между кодами данных и команд. Например, в некоторых случаях нужна большая и сложная программа, а данных в памяти надо хранить не слишком много. В других случаях, наоборот, программа требуется простая, но необходимы большие объемы хранимых данных. Перераспределение памяти не вызывает никаких проблем, главное – чтобы программа и данные вместе помещались в памяти системы. Как правило, в системах с такой архитектурой память бывает довольно большого объема (до десятков и сотен мегабайт). Это позволяет решать самые сложные задачи.
Архитектура с раздельными шинами данных и команд сложнее, она заставляет процессор работать одновременно с двумя потоками кодов, обслуживать обмен по двум шинам одновременно. Программа может размещаться только в памяти команд, данные – только в памяти данных. Такая узкая специализация ограничивает круг задач, решаемых системой, так как не дает возможности гибкого перераспределения памяти. Память данных и память команд в этом случае имеют не слишком большой объем, поэтому применение систем с данной архитектурой ограничивается обычно не слишком сложными задачами.
Преимущество архитектуры с двумя шинами(гарвардской) заключается прежде всего в высоком быстродействии. Дело в том, что при единственной шине команд и данных процессор вынужден по одной этой шине принимать данные (из памяти или устройства ввода/вывода) и передавать данные (в память или в устройство ввода/вывода), а также читать команды из памяти. Естественно, одновременно эти пересылки кодов по магистрали происходить не могут, они должны производиться по очереди. В случае двухшинной архитектуры обмен по обеим шинам может быть независимым, параллельным во времени. Соответственно, структуры шин (количество разрядов кода адреса и кода данных, порядок и скорость обмена информацией и т.д.) могут быть выбраны оптимально для той задачи, которая решается каждой шиной.
Слайд 24Функции устройств ввода/вывода Устройства ввода/вывода обмениваются информацией с магистралью по тем
же принципам, что и память. Устройства ввода/вывода взаимодействуют еще и с внешними устройствами, цифровыми или аналоговыми. Быстродействие устройств ввода/вывода может значительно отличаться от быстродействия остальной микропроцессорной системы.Разнообразие устройств ввода/вывода неизмеримо больше, чем модулей памяти. Устройств ввода/вывода могут иметь другие названия:устройства сопряжения, контроллеры, карты расширения, интерфейсные модули и т.д.
Объединяют все устройства ввода/вывода общие принципы обмена с магистралью и, соответственно, общие принципы организации узлов, которые осуществляют сопряжение с магистралью.
